
New Week #137
AI is generating a huge row about the rights of artists and creators

Welcome to this update from New World Same Humans, a newsletter on trends, technology, and society by David Mattin.
If you’re reading this and haven’t yet subscribed, join 25,000+ curious souls on a journey to build a better future 🚀🔮
To Begin
The music industry wants to take down AI-fuelled pop music generators. Its message? We’ll see you in court.
That is just one dimension of a broader row, growing more intense by the month, between the owners of IP and generative AI startups. This week, I dive in.
Also, a look at the largest global survey ever conducted on attitudes to climate change.
Let’s go!
🧠 Who owns the hivemind?
This week, two happenings cast light on the strange new relationship now taking shape between humans and intelligent machines.
A host of record label giants, including Universal Music Group and Sony, are suing AI music generators Udio and Suno. The lawsuit, led by the Recording Industry Association of America, alleges that the startups used copyrighted material to help train their AI models: an act that amounts, says the Association, to ‘copyright infringement on an almost unimaginable scale’.
Udio and Suno have both made headlines recently for their ability to generate compelling and authentic-sounding pop songs via a simple natural language prompt.

But the Association says music generated by Udio and Suno is set to ‘saturate the market with machine-generated content that will directly compete with, cheapen and ultimately drown out the genuine sound recordings on which the services were built.’
Meanwhile, Meta is facing a challenge from European authorities over its AI plans. The social giant wants to scrape the Facebook and Instagram posts of European users to train its AI models, but has been forced to put the plan on hold after the intervention from the Irish Data Protection Commission.
Meta says that it wants to to use European user posts as training data so that its AIs understand ‘Europe’s rich cultural, social and historical contributions’. The company says it hopes the legal challenges it faces will be resolved soon, and that in the meantime it won’t launch Meta AI in Europe.
⚡ NWSH Take:
Via this new lawsuit, the giants of the music industry are making their position clear when it comes to the generative AI revolution.
And they’re tapping into a consequential issue set to play out through the courts — and make lawyers rich — for years to come: is it okay to scrape copyrighted work from the web to train an AI model?
A thousand and one lawsuits will bloom over this question. There are already more than a few: see the New York Times and its action against OpenAI.
So, is it okay? The answer, surely, is no. Not, at least, if copyright still means anything. Using IP as training data without permission is the equivalent of stealing cakes from other bakeries, whisking them together into a whole new cake, and then taking them to market while shouting does anyone fancy some cake that’s very much like the cake we all buy from those other bakeries?
Over on X, former Stability AI staffer Ed Newton-Rex has been waging a long campaign on this issue. (Side note: his father taught me early-modern English history at university; small world). Here is Newton-Rex taking on Mustafa Suleyman, now head of Microsoft AI, who says content on the web is ‘freeware’:

Right now, AI insurgents and tech giants alike are taking the classic Silicon Valley approach: don’t ask for permission, ask for forgiveness. Their raid on protected IP is remiscent of the way Uber exploded across the globe, broke established public transport regulations in city after city, and then fought the resulting legal battles.
The argument will run on. But I can’t see how the courts can avoid the conclusion, in the end, that you can’t simply take protected IP and use it to build new commercially available products.
That will mean a reordering of the way models are trained and made available to the public. Model owners will be forced, I suspect, to be more transparent about training data. And they’ll have to seek permission for the owners of IP they want to use as training material, and make arrangements to compensate those owners.
In the end, this will become a powerful new source of revenue — perhaps one of the most important sources — for IP owners and creators. Think of the licensing fees that the estate of, say, Picasso can make from a proprietary PicassoGPT. Think of the cultural power and reach of a proprietary TaylorGPT trained on Swift’s songs, and endorsed by her.
As I’ve written about before, we’ll come to see the biological lifespan of an artist as just the first stage in an extended creative journey. During their life the artist will create original work that leaves their unique imprint — something akin to a creative fingerprint — on an AI model. And then that model generates new output forever.
In the end this is where much of the value around generative AI will be built. Ordinary LLMs and text-to-image models are going to become commodities; there will be lots of them, and many of them will be great. Their outputs will be as abundant as tap water. The real rewards will flow to those who have inputs — content, data, creative works — that can be used to coax enhanced outputs from those models.
This can be an amazing world for artists and creatives.
The strategy, then, for creators of all kinds should be clear. They should support legal challenges against those suspected of using protected IP as training data. And, crucially, they should seize the means of intelligence, by leveraging open source models to create custom AIs trained in their unique styles and perspectives.
Get all that right, and creators can be the real long-term winners when it comes to the generative AI revolution.
🌍 Global climate consensus
We’ve all heard how this year is set to be a significant one for global democracy. By the end of 2024 over 1.5 billion people will have voted in national elections in India, Russia, the UK, the US, and beyond.
But this week saw the results of another major democratic process made public. The UN published The Peoples’ Climate Vote, a report on the largest ever survey of attitudes to climate change.
The project saw questions put to 75,000 people in 77 countries, representing almost 90% of the global population. And the results indicate a significant consensus on the need for deeper and faster action.
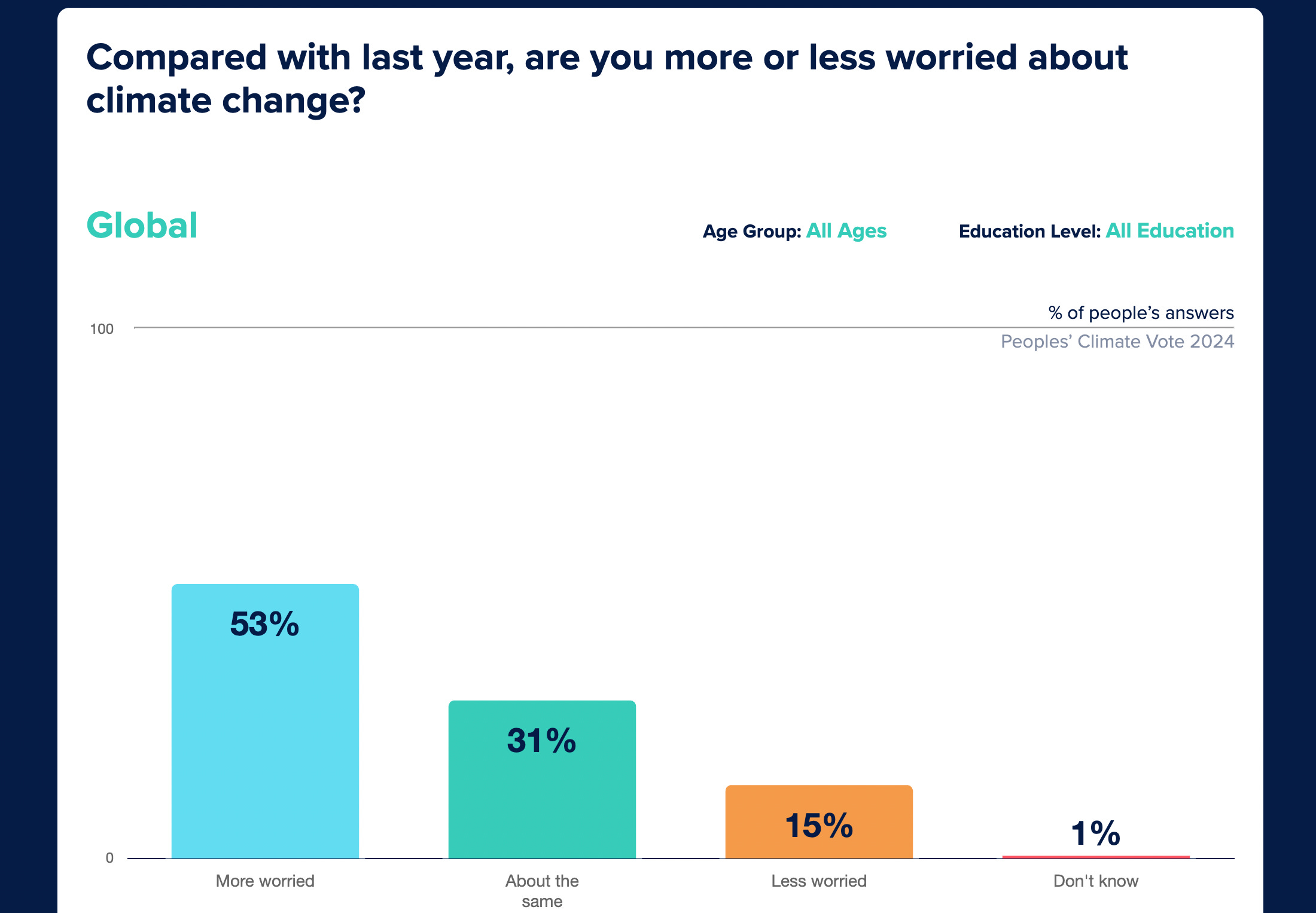
A majority of people worldwide said they are more worried about climate change now than they were last year:
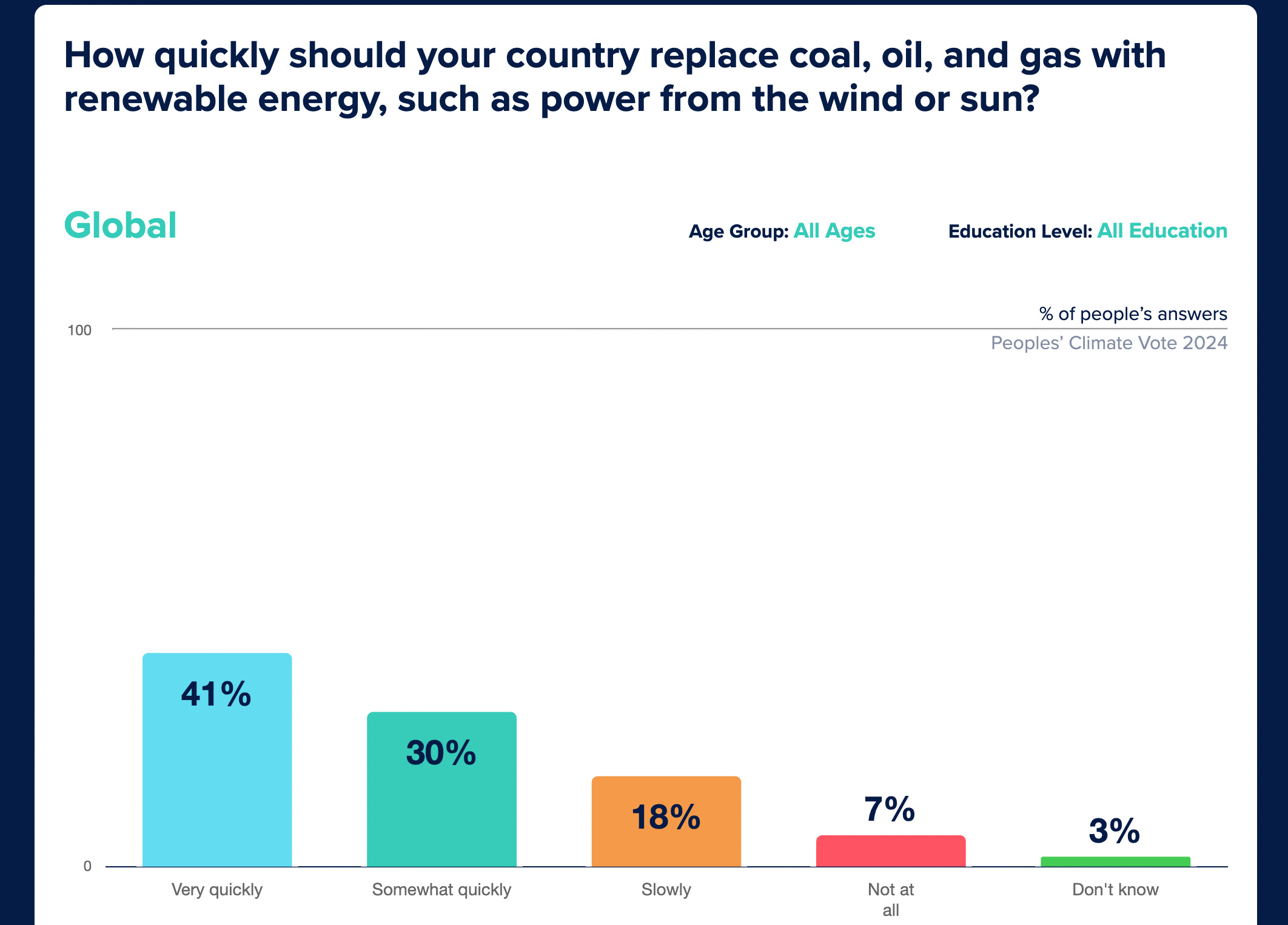
And a majority said they want their government to transition to clean energy ‘very quickly’ or ‘somewhat quickly’:
One of the most significant findings?
In countries most associated with fossil fuel production, significant majorities want a fast transition away from them. In the US — the world’s largest producer of oil and fast — 54% want a fast transition. In Saudi Arabia, that number is 75%.
⚡ NWSH Take:
This UN survey is a major achievement in its own right, and on the Peoples’ Vote site you can read about how researchers put 15 questions to 75,000 people worldwide while maintaining standards of neutrality and fairness.
The raw data is pretty clear: most people are worried about climate change and want both government and big business to do more about it. Given the size of the population surveyed here, the findings are significant.
Still, these kinds of surveys are vulnerable to certain kinds of criticism. It’s easy to get people to say that they’d like climate change to go away. But ask them what if they are, for example, willing to bear the costs of more expensive energy, and some might sing a different tune.
In 2024, though, the answer to that challenge is emerging.
Trump has promised to roll back environmental protections and green energy policies if he wins in November. He wants to support the US fossil fuel industry. And he’s betting that US citizens will vote for, as they see it, cheaper energy prices.
The truth, though, is that if Trump tries to roll back the advance of green energy he’ll be fighting a losing battle. Solar and wind are becoming so cheap, they’re out-competing fossil fuels on cost alone. In many cases in the US it is now cheaper to deploy new solar energy plants than it is to continue to run coal-fired power stations.
The next pressing quest will be to deal with the challenges that a transformed energy grid brings with it, including intermittency and storage.
In the meantime, watch: we’re going to see ever-more rapid transition towards green energy. Not because the public wants it, but because the money imperative is at work.
Super Models
Thanks for reading this week.
The growing row over the rights of IP owners in an age of generative AI is a classic case of new world, same humans.
I’ll keep watching, and working to make sense of it all. And there’s one thing you can do to help: share!
Now you’ve reached the end of this week’s instalment, why not forward the email to someone who’d also enjoy it? Or share it across one of your social networks, with a note on why you found it valuable. Remember: the larger and more diverse the NWSH community becomes, the better for all of us.
I’ll be back next week with another update from the new world we’re building. Until then, be well,
David.
The answer to the issue of rights of artists and creators in the training of ai models is clear, as you suggested an open model that tracks inputs into training an LLM or similar ai and allows for compensation of artists that contribute. I know of one solution already like this and I am sure there are others I am not aware of.
From your lips to God‘s ear